It has almost been a decade since the invention of modern implementations of Gradient Boosted Decision Trees (GBDT), such as XGBoost [Chen and Guestrin 2016], LightGBM [Ke et al 2017], and CatBoost [Prokhorenkova et al 2018]. Over the years, these GBDTs have become the industry standard machine learning methods for predictive modeling tasks (classification and regression), thanks to their superior predictive accuracy and computational efficiency. On the other hand, with the rapid development of deep learning techniques, many attempts have been made to create novel Tabular Deep Learning (TDL) methods that can yield comparable performance with GBDT or even outperform them. In addition, there are also multiple empirical works that propose new benchmarks to horserace deep neural network (DNN) methods against GBDT, with growing number of datasets and extensive analysis on which methods perform well on which types of data.
In this post, I will give a high-level overview of several benchmark papers (disclaimer: by no means this aims to be a complete survey), mainly including Grinsztajn et al 2022, McElfresh et al 2023, TabReD [Rubachev et al 2025], and TALENT [Ye et al 2025]. I will mainly focus on
- What types of datasets are in the benchmarks?
- What DNN and/or GBDT models rank the top?
- What properties of the data may impact the “DNN vs GBDT” comparison?
- What insights can we get to make the models better?
Note that like GBDTs, TDL models are created for traditional tabular data rather than sequential tabular data. For the former, conditional independence (exchangeability) applies, while for the latter, multiple events are associated with the same individual and usually happen in a temporal order.
Datasets
The more the merrier, but diversity and quality matter.
| Grinsztajn et al 2022 | McElfresh et al 2023 | TabReD [Rubachev et al 2025] | TALENT [Ye et al 2025] | |
|---|---|---|---|---|
| # Datasets | 45 | 176 | 8 | 300 |
| Sources# | OpenML | OpenML | Kaggle, and a new private industry data source | UCI Machine Learning Repository, Kaggle, and OpenML |
| Highlights | A wide range of sample sizes: from 32 to 1 million. | Real industry standard data, with \(n_\text{sample}\) on the million scale, and median \(n_\text{feature}\) more than 200. Has timestamps to split data along, and the data may experience gradual temporal shift. Includes engineered features so the data have higher collinearity and redundancy. |
120 binary classification datasets, 80 multi-class classification datasets, and 100 regression datasets. |
|
| Limitations | \(n_\text{feature} / n_\text{sample} < 0.1\) Focus on medium-sized data: \(n_\text{sample} < 10,000\) |
All classification data | Only 8 datasets, hard to conclude statistical significance | Most \(n_\text{sample}\) are on the \(10^4\) and \(10^5\) scale, with only several datasets more than \(10^6\) Most \(n_\text{feature}\) are small, with only about about 2 dozens exceeding 100 |
| Mini-benchmarks | TabZilla: 36 hardest datasets | Two mini-benchmarks, 45 datasets each: (1) Tree-friendly vs DNN-friendly (2) Rank consistent |
Note that a lot of OpenML datasets are originally from UCI Machine Learning repository or Kaggle.
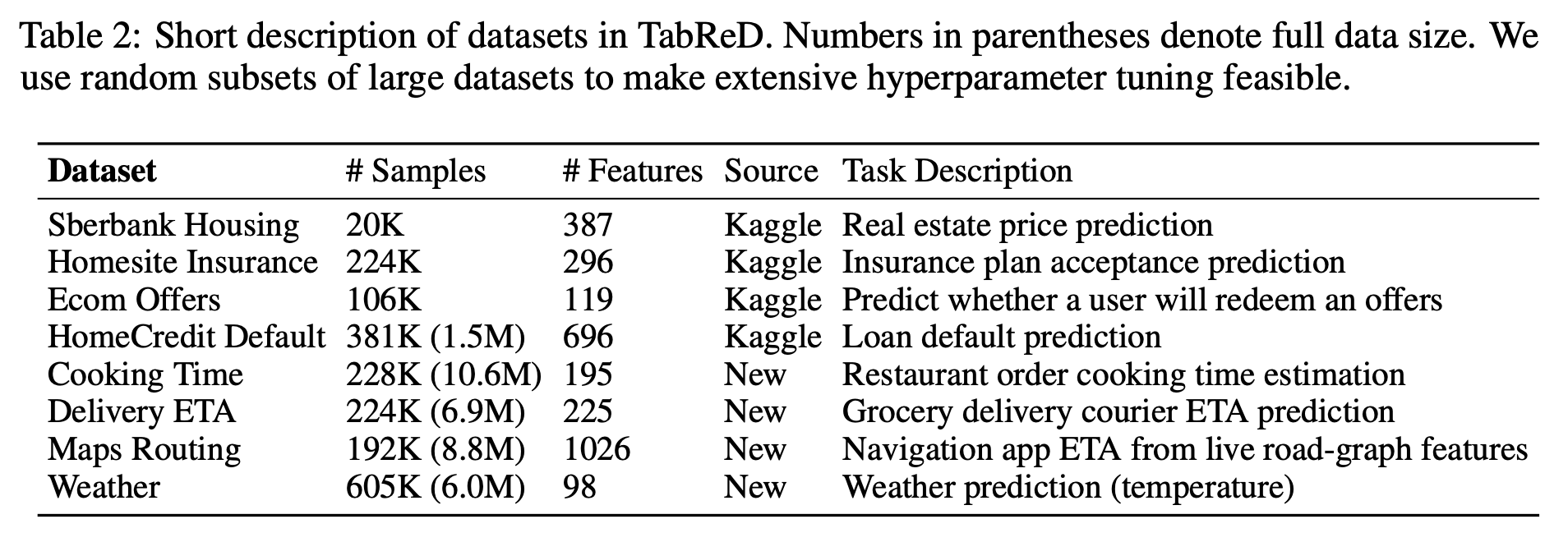
Since TabReD may be relevant and helpful for data scientists working in the industry like myself, I attach the dataset overview of it here. Source: the TabReD paper [Rubachev et al 2025].
Models
The more the merrier, again, but implementation and optimization matter.
| Grinsztajn et al 2022 | McElfresh et al 2023 | TabReD [Rubachev et al 2025] | TALENT [Ye et al 2025] | |
|---|---|---|---|---|
| # models | 7 | 19 | 18 | 32 |
| Top ranking models | XGBoost | CatBoost | MLP-PLR ensemble | CatBoost |
| Top ranking DNN models | FT-Transformer, SAINT | TabPFNv1 | MLP-PLR ensemble | TabR, ModernNCA, RealMLP, |
| Top ranking GBDT models | XGBoost | CatBoost | XGBoost | Catboost |
| Objective function: classification | Accuracy | Accuracy | Cross entropy | Accuracy |
| Objective function: regression | \(R^2\) | No regression data in this benchmark | MSE | RMSE |
| Hyperparameter tuning | Random search, 400 trials | Random search, 30 trials | Optuna | Optuna, 100 trials |
| Limitation | Categorical features are only handled by one-hot encoding (but not embedding) for all models | For large datasets, TabPFN(v1) is run on a random sample of 3000 data points. Due to computation budget constraints, main results are based on 98 (likely smaller or easier) datasets. |
Comparisons are based on random large subsamples of the data | |
| Notes | Numerical features are Gaussianized for DNN | Train-valid-test split is along a temporal variable, thus it’s harder than random split |
Overview of top ranking models
Before introducing the promising models, I want to emphasize that there exists huge variation across datasets. Although some GBDT and DNN models consistently perform well on a lot of datasets, there is no single model dominating all datasets. In McElfresh et al 2023, almost every one of the 19 benchmarked models rank the best on some datasets, and rank at the bottom on some other datasets. For the TALENT benchmark, even simple linear models, such as logistic regression, perform the best on 5% of the binary classification datasets.
In the following part, I will briefly cover the performance of each type of models. Here, I subcategorize the DNN models mostly following the categorization of the TALENT benchmark paper [Ye et al 2025].
GBDT: XGBoost, LightGBM, and CatBoost are equally the best
A first consistent trend is that these three GBDT models remain to be among the best. Among these three, some benchmark works find Catboost the best, while some find XGBoost the best. Wilcoxon-Holm tests in the TALENT benchmark paper suggest that there is no significant difference among the three.
One interesting observation from the TabReD benchmark is that when changing the train-valid-test data split method from random split to splitting along a temporal variable, the advantage of GBDT over DNN models becomes smaller.
MLP variants: RealMLP is better than vanilla MLP and ResNet
In the benchmark papers, the MLP and ResNet models follow the same architecture as in Gorishniy et al 2021:
- MLP: fully connected neural network, with ReLU activation and dropout
- ResNet: the above MLP, plus batch norm and residual connection every two layers
Gorishniy et al 2022 proposes methods to embed continuous features which can improve MLP models’ performance. This is confirmed by the TabReD and TALENT benchmarks, i.e., MLP-PLR outperforms MLP.
The best performing MLP variants is RealMLP [Holzmüller et al 2024], which optimizes MLP performance with a lot of design choices, including the above mentioned continuous feature embeddings. It is among the top ranking models in both the TALENT benchmark and another new benchmark called TabArena [Erickson et al 2025]. In fact, Wilcoxon-Holm tests in the TALENT benchmark finds that the improvement of RealMLP over MLP and ResNet is statistically significant.
Retrieval-based (Neighborhood-based) DNN: TabR and ModernNCA
Retrieval-based DNN models use KNN to learn local structures. The best ones are TabR [Gorishniy et al 2024] and ModernNCA [Ye et al 2025]. They are among the top ranking DNN models in both the TALENT and TabArena benchmarks. Moreover, Wilcoxon-Holm tests in the TALENT benchmark find no significant difference among the three GBDTs and ModernNCA.
On the large and messy datasets in the TabReD benchmark, both TabR and ModernNCA lose their edge and are beaten by all three GBDTs, MLP-PLR, and even MLP. Possible reasons may be that industry standard datasets’ complex feature multicolinearity and redundancy make it harder to find good neighborhood, and also the retrieval-based approaches can be less robust to the temporal shift in the data.
Ensemble DNN: TabM
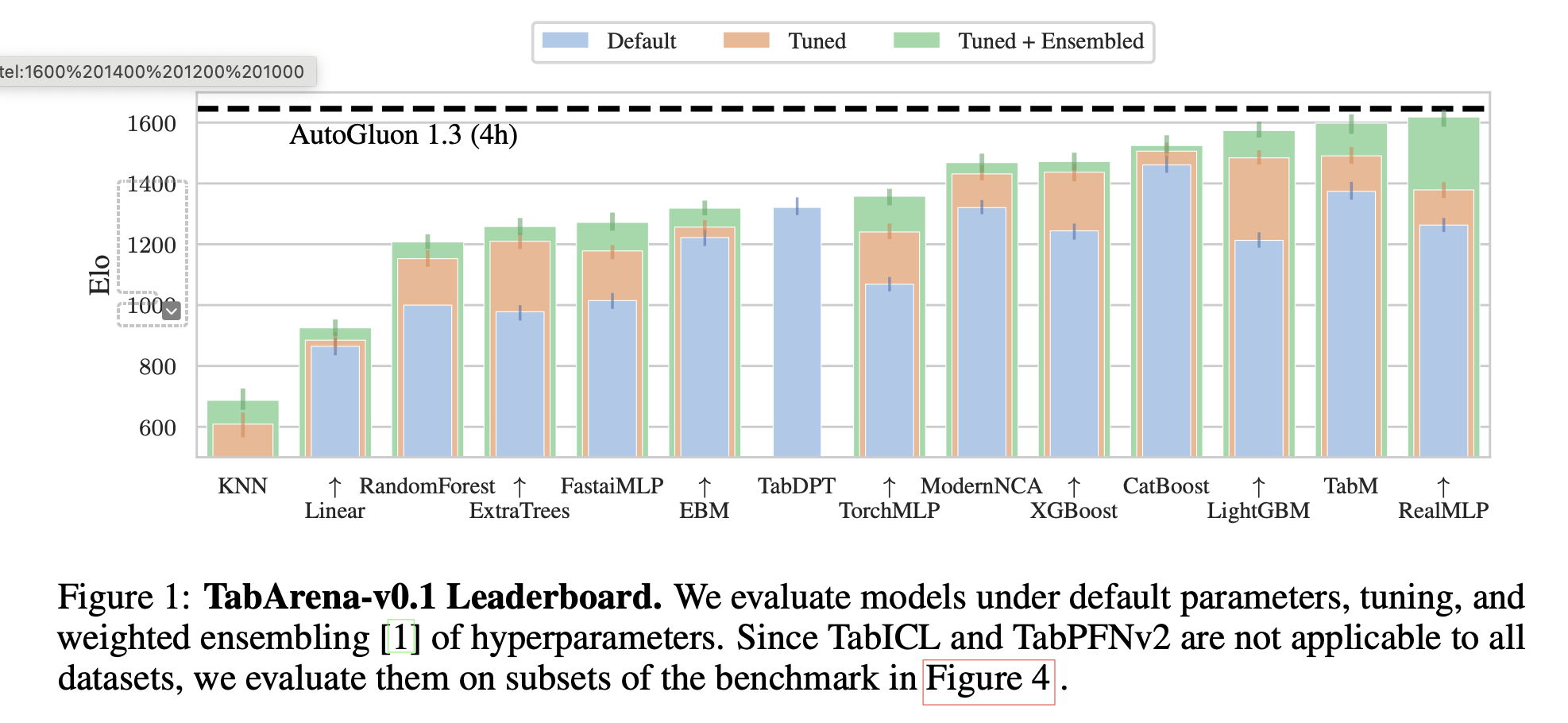
Based on MLP architecture, TabM [Gorishniy et al 2025] introduces parameter-efficient ensemble, where the underlying MLPs share a lot of parameters. Thus, by ensembling a lot of these potentially weaker learners, TabM achieves top performance, comparable with RealMLP, as shown in the more recent benchmark works TabArena and Zabërgja et al 2025.
Token-based (Transformer-based) DNN: not so promising compared with MLP
Many transformer-based DNN models are benchmarked, with the most promising one being FT-Transformer [Gorishniy et al 2021]. However, Wilcoxon-Holm tests in the TALENT benchmark find no significant difference among most token based methods.
I feel like that a recent trend in TDL is to turn away from transformer-based models to embrace MLP-based models again. In fact, there is no transformer-based models (except the PFNs, which use the transformer architecture, but are foundation models that are pre-trained on synthetic data) ranks within top 3, in any of the more recent benchmarks, TabReD, TALENT, and TabArena. In McElfresh et al 2023, token-based models are outperformed by ResNet. Also, Grinsztajn et al 2022 finds that transformer based methods tend to perform better on smaller data, whose sample size is smaller than \(10,000\).
Tabular foundation models: PFNs are the best with small data
I personally think it may make more sense to list the Prior-Fitted Networks (PFNs) separate from the above token-based DNNs. PFNs are foundation models pre-trained on synthetic data. Using the few-shot learning ideas in large language models, when given a new training and test data pair, the attention mechanism in PFNs enables them to learn the training data’ information during the scoring time, and apply them to make prediction in the test data. Thus, they achieve very fast training speed (no parameter learning or fine-tuning needed, just model scoring). As a Bayesian statistician, I still need more time to understand PFNs, since they seem so mysterious but surprisingly powerful on small datasets.
PFNs are the top ranking models, but just with small datasets so far. In McElfresh et al 2023, TabPFNv1 [Hollmann et al] is the best among DNN models. On small datasets (sample size less than 3000), it enjoys fast training time, comparable to linear model and KNN. But its inference time is not so fast compared to all other models. In the recent benchmark TabArena, TabPFNv2 [Hollmann et al. 2025] ranks the best model among datasets with sample size up to \(10,000\) and TabICL [Qu et al 2025] ranks the third best among datasets with sample size up to \(100,000\), only losing to TabM and RealMLP.
Details of model comparison results from the papers
-
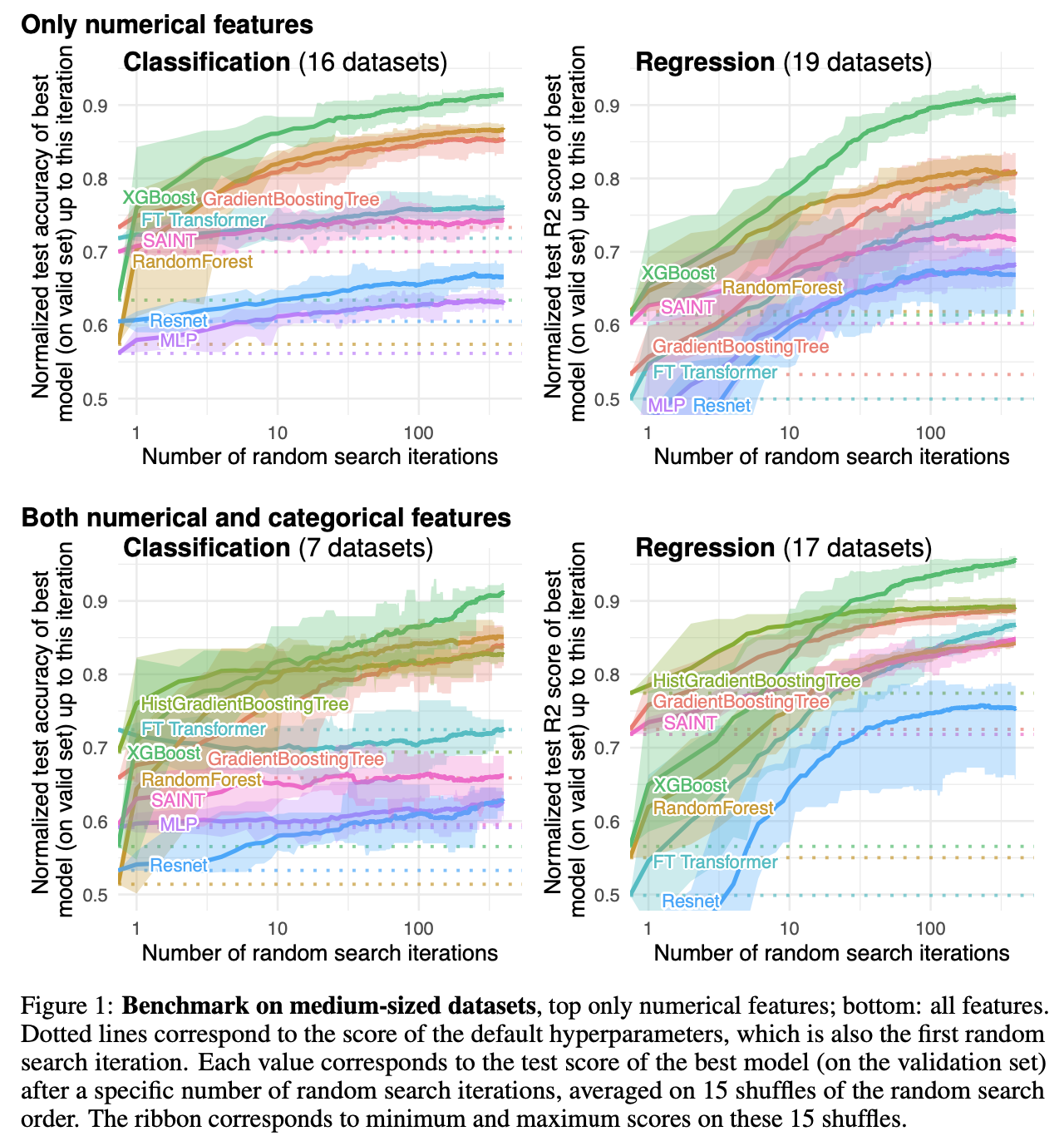
From McElfresh et al 2023: there is no single model dominates, suggesting huge variation across datasets.
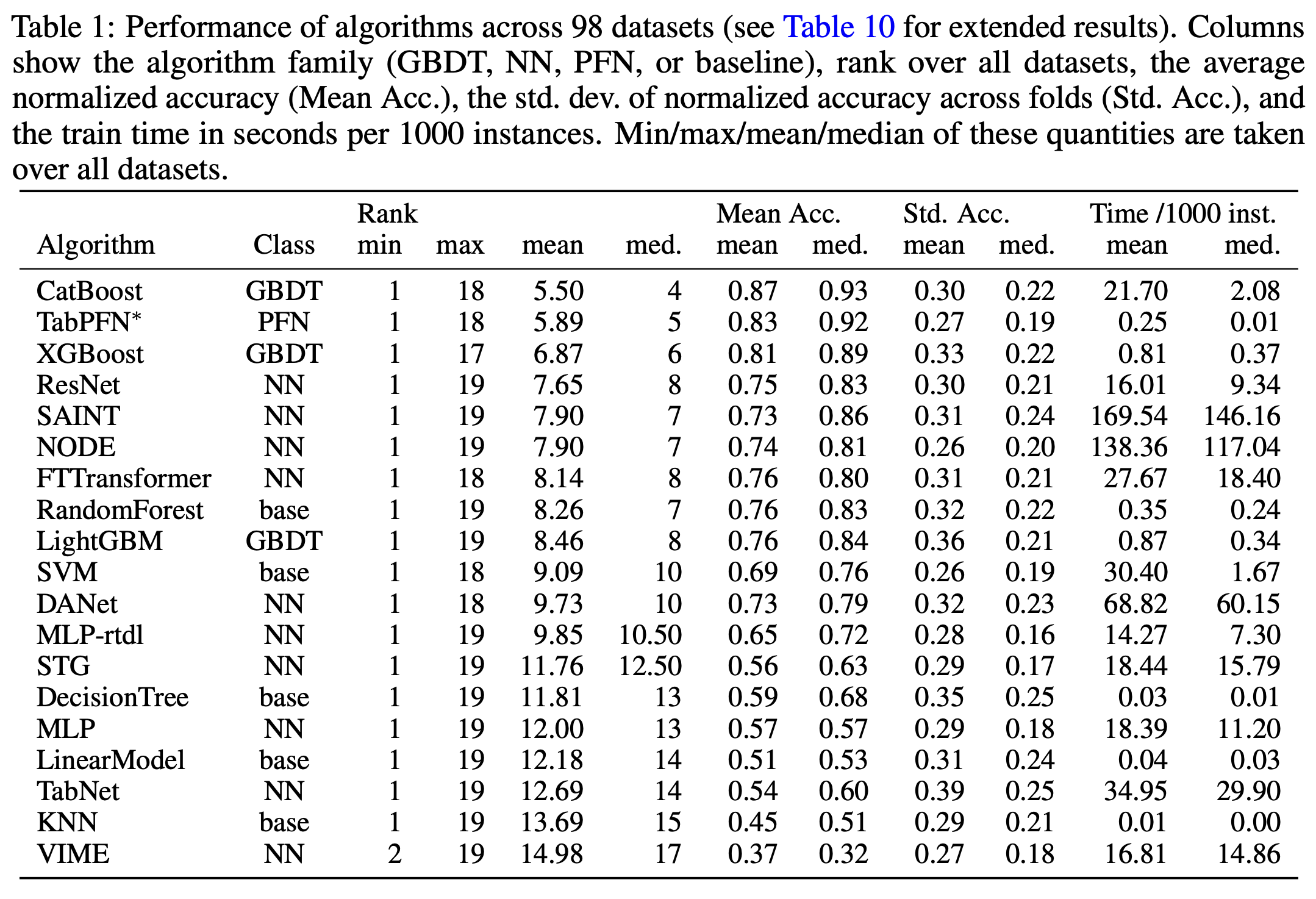
From the TabReD paper [Rubachev et al 2025]: for industry standard data (large and messy), the three GBDT models plus ensembles MLP-PLR are the best.
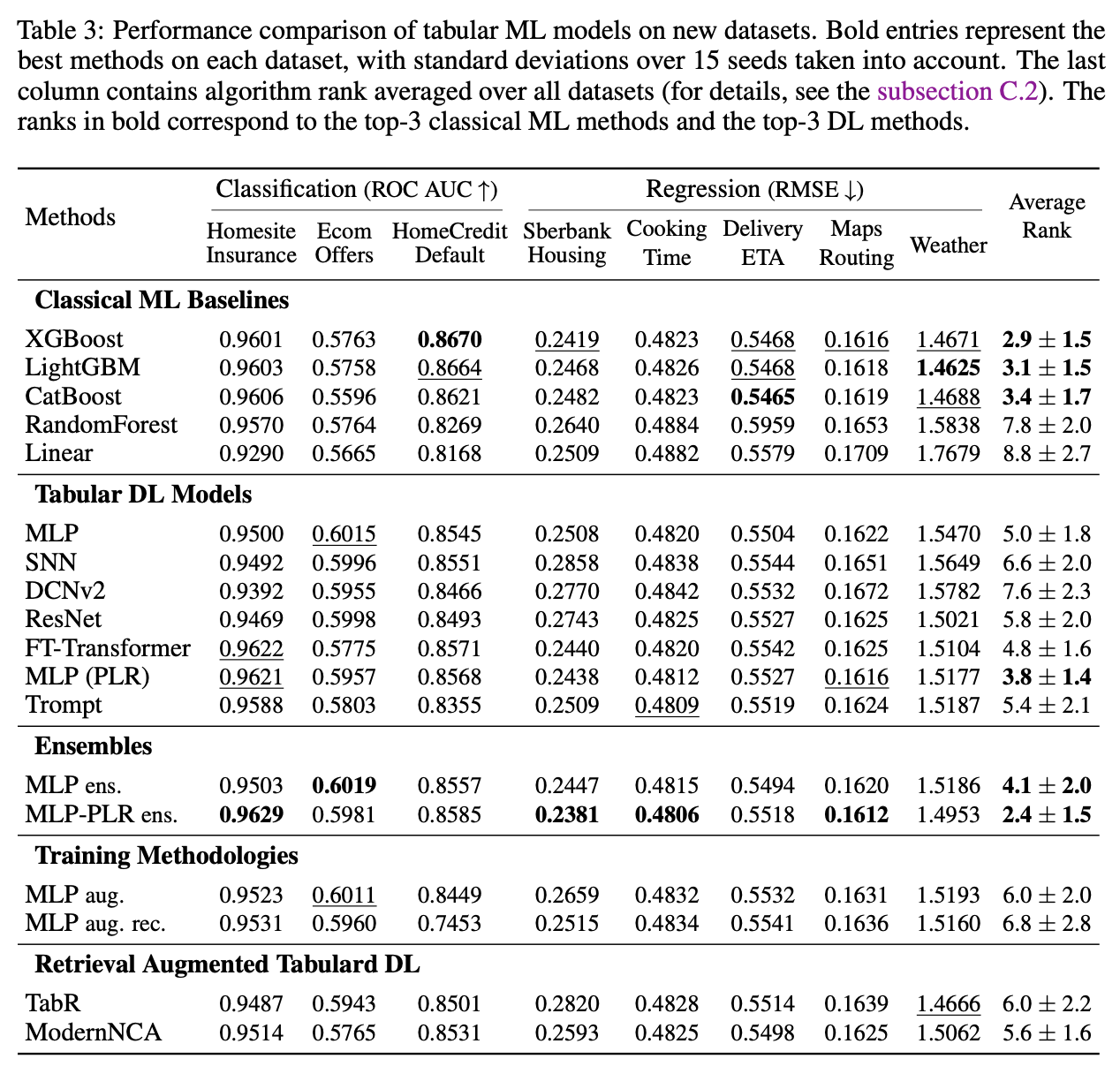
From the TALENT benchmark paper [Ye et al 2025]
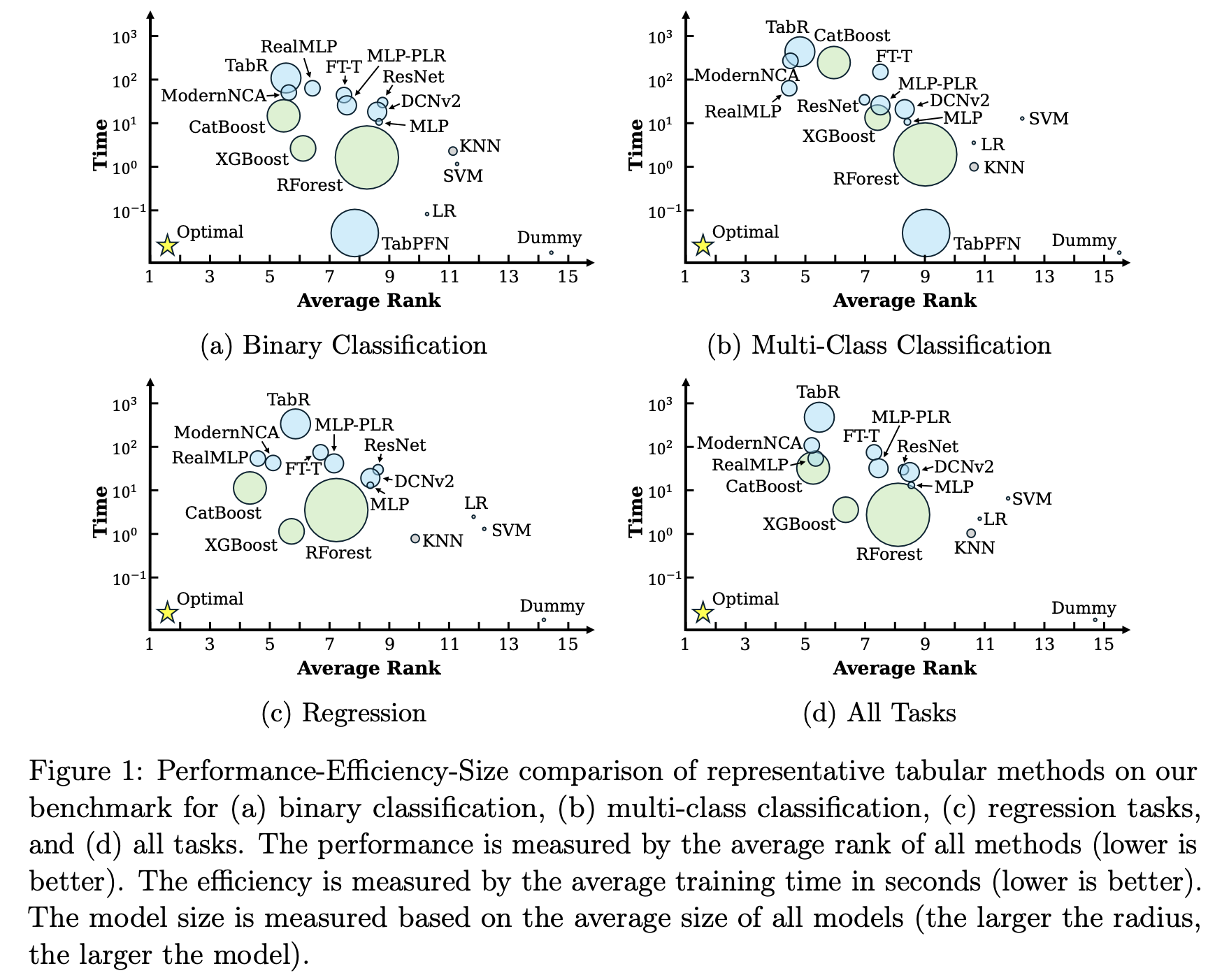
From TabArena paper [Erickson et al 2025]
When does GBDT outperform DNN
Large sample size
McElfresh et al 2023 computes correlation between datasets’ meta-features and normalized log loss, and finds that the most highly correlated meta-feature for XGBoost and LightGBM is the log sample size. In other words, the higher the sample size, the better XGBoost and LightGBM performs. In addition, the log sample size has the highest correlation with the performance gap between best GBDT vs best DNN.
Ye et al 2025 finds that Catboost consistently outperform neural network method on large data, whose \(n_\text{samples} > 10^4\) (Well, not so large, right? 😅). TabR also performs well on large data, but not MLP or FT-Transformer.
Feature redundancy
Since GBDT models select which features to split along, it can be less vulnerable to feature redundancy. In contrast, DNN models seem to suffer more in the presence of redundant features.
Grinsztajn et al 2022 finds that after removing uninformative features based on random forest’s feature importance, the performance gap between GBDT and DNN models decreases as more features are removed. McElfresh et al 2023 finds the ratio \(n_\text{sample} / n_\text{feature}\) is the 2nd highest correlated meta-feature with GBDT vs DNN performance gap. Since \(n_\text{feature}\) also includes redundant features, this finding also backs up the hypothesis that redundant features hurt DNN performance more. In the benchmark TabReD, where datasets are large and messy, and thus have more complex correlation and redundancy, all DNN models (except MLP-PLR ensembles) lose to GBDT models.
This suggests that feature screening as a pre-processing step and feature selection during the training could be an essential step to improve DNN performance. Of course, GBDT models usually also benefit from careful features screening and selection.
Feature heterogeneity and irregularity
GBDT models are found to perform better on datasets with higher variance of skewness, sparsity, entropy, and IQR, among all the features. More specifically, McElfresh et al 2023 finds that GBDT outperforms DNN more often with higher
- Max skewness of all features,
- Range of skewness of all features,
- Standard deviation of feature skewness, and
- Standard deviation of feature kurtosis.
Ye et al 2025 finds that GBDT ranks better than DNN as the following meta-features increases:
Standard deviation of sparsity. Here, the sparsity for a feature vector \(v\) that has \(\phi(v)\) unique values is defined as \[ S(v) = \frac{1}{n-1}\left(\frac{n}{\phi(v)}-1 \right)= \frac{1}{\phi(v)}\frac{n - \phi(v)}{n-1}, \] where \(n\) is the sample size
Standard deviation of entropy, where the entropy of a feature is defined as \[ H(v) = -\sum_k p_k \cdot \log (p_k) \] Here, \(p_k\) is the proportion of the \(k\)-th unique value.
Standard deviation of interquartile range (IQR).
Regression and binary classification tasks
The TALENT benchmark [Ye et al 2025] compares models in three separate types of predictive modeling tasks: binary classification, multi-class classification, and regression, and finds that DNN models outperform GBDT for multi-class classification, but not for binary classification or regression.
My guess is that the L2 loss used for regression tasks may not be the most suitable for some continuous targets dataset, since the target may be heavily skewed, so that they may need log transformation or Tweedie regression instead of normal regression. Tree based models might be more robust against misspecification of loss function than DNN models.
On the other hand, for multi-class classification tasks, some GBDT models such as XGBoost and LightGBM usually fit separate trees, one for each class, while in MLP methods, different classes share the same network architecture until the very last layer. Maybe the efficient parameter sharing contributes to DNN models’ better performance in multi-class classifications.
Non-smooth target functions
Since DNN methods tend to give smoother solutions than GBDT, Grinsztajn et al 2022 performs an experiment to smooth the target function though a Gaussian Kernel smoother, and finds that as the solution becomes smoother, the performance gap between GBDT and DNN becomes smaller, and eventually FT-Transformer outperforms GBDT.
Other factors
Rotation invariance
Grinsztajn et al 2022 comments on the rotation invariance, i.e., invariance after the features being multiplied by an orthogonal matrix. MLP-based models are rotation invariant, but the data are usually not. Therefore, this might be a reason why MLP loses to non rotation invariant models such as GBDT and token-based models.
Accuracy metrics
Ye et al 2025 finds that with imbalanced data, the choice of evaluation metrics matters to the ranking of models. More specifically, AUC favors GBDTs and TabPFN, while F1-score favors RealMLP.
Insights and Learnings
When I discussed these benchmark papers with my mentor and data science colleagues, the first question they asked was “whether the GBDT models were treated fairly to optimize their performance”? I have to admit that this is a very reasonable doubt since the benchmark papers were mostly written by researchers who develop new DNN models. Of course, their unspoken (or maybe explicit, anyway) hope is for DNN model to beat GBDT models, or at least, to identify which DNN models can. On the other hand, the GBDT models are improving over the decade since they were created, just to name a few recent innovations:
- Both XGBoost and LightGBM use histogram binning as a feature pre-processing to accelerate tree split search speed.
- LightGBM uses optimal partition to handle categorical features more efficiently, so that one-hot encoding is no longer needed. XGBoost can do this, too, but it is not the default setting so users need to turn it on.
- LightGBM has Cost Efficient Gradient Boosting (CEGB), which penalize a feature when it first appears in a tree. This is a very interesting feature selection mechanism and definitely worthy trying.
- I’m not that familiar with CatBoost, but I think the focus on oblivious tree, where each layer of a tree split on the same feature at the same cut point is quite cool and powerful to prevent over-fitting.
With that being said, these benchmark papers serve as great introduction materials for one to quickly get a solid grasp on the TDL literature and to identify promising models to dig further,
In addition, some of the insights in the papers can be valuable to improve both DNN models and GBDTs.
- As feature redundancy in the data is a real problem, I think feature screening and feature selection can be very important.
- Hyperparameter tuning is important. As emphasized in McElfresh et al 2023, “light hyperparameter tuning on CatBoost or ResNet increases performance more than choosing among GBDTs and NNs.”. I think rather than random search, using some Bayesian optimization algorithm, such as TPE (the default sampler of Optuna) would be better.
- Data pre-processing can be essential. For continuous features, both DNN and GBDT may be beneficial from feature binning, feature transformation (to be less skewed), or embeddings in Gorishniy et al 2022. For categorical features with high cardinality, rather than learned embedding, random effects may be worth trying [Simchoni and Rosset 2023].
References
Chen and Guestrin. “Xgboost: A scalable tree boosting system.” SIGKDD, 2016
Ke et al. “Lightgbm: A highly efficient gradient boosting decision tree.” NeurIPS, 2017
Prokhorenkova et al “CatBoost: unbiased boosting with categorical features” NeurIPS, 2018
Grinsztajn, Oyallon, and Varoquaux “Why do tree-based models still outperform deep learning on typical tabular data?” ICML 2022 (Github repo)
McElfresh et al. “When do neural nets outperform boosted trees on tabular data?” NeurIPS, 2023 (Github repo)
Rubachev et al “TabReD: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks” ICLR, 2025 (Github repo)
Ye et al. “A Closer Look at Deep Learning on Tabular Data.” arXiv: 2407.00956 (2025) (Github repo)
Gorishniy et al. “Revisiting deep learning models for tabular data.” NeurIPS, 2021
Gorishniy et al. “On embeddings for numerical features in tabular deep learning.” NeurIPS, 2022
Holzmüller et al. “Better by Default: Strong Pre-Tuned MLPs and Boosted Trees on Tabular Data” NeurIPS, 2024
Erickson et al. “TabArena: A Living Benchmark for Machine Learning on Tabular Data” arXiv: 2506.16791 (2025)
Gorishniy et al. “TabR: Tabular Deep Learning Meets Nearest Neighbors.” ICLR, 2024
Ye et al. “Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later”, ICLR, 2025
Gorishniy, Kotelnikov, and Babenko. “TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling” ICLR 2025
Zabërgja et al. “Tabular Data: Is Deep Learning You Need?” arXiv: 2402.03970 (2025)
Hollmann et al. “Tabpfn: A transformer that solves small tabular classification problems in a second.” ICLR, 2023
Hollmann et al. “Accurate predictions on small data with a tabular foundation model” Nature, 2025
Qu et al. “TabICL: A Tabular Foundation Model for In-Context Learning on Large Data”, ICML, 2025
Simchoni and Rosset “Integrating random effects in deep neural networks”, Journal of Machine Learning Research, 2023